
Decoding Amphibian Vocalizations with Flutter and Tensorflow Lite
Hello everyone! 🖖
This time, I want to share with you the journey of one of the most extravagant yet fascinating applications we’ve had to develop so far.
Its name is Croalitoral, and it’s capable of identifying up to 25 species of amphibians based solely on their calls.
Here’s a little preview for you.

The application originates from the biologist and researcher of Conicet (National Council for Scientific and Technical Research), Evelina Leon. She needed to identify amphibians in nature based on their calls using her cell phone.
Clearly, this was an idea that didn’t just pop out of our heads 😅.
With no prior experience in the field of audio classification, we thought of turning to Tensorflow, a tool we had already worked with for image recognition.
We started developing our own recognition models, and despite not having much knowledge of training models of any kind, by following some tutorials, we managed to achieve relatively good results. However, all these models were running on my computer (Lenovo Legion Y720), which had certain features that aided their performance.
And here is where our first problem showed up. 😢
These models needed to be accessible from anywhere, which meant we needed a server with specifications similar to my computer, which was very expensive.
If we add to this the premise that the application had to identify amphibians in the middle of nature (a place where there usually isn’t a great signal), it became nearly impossible to use these models.
 No connection
No connection
That’s when we turned to Tensorflow Lite.
TensorFlow Lite (TF Lite) is an optimized and lightweight version of TensorFlow, specifically designed to run machine learning models on mobile devices, IoT devices, and other systems with limited resources. But most importantly, it doesn’t require an internet connection as it runs locally and in real-time.
This put us back on track with a small detail.
The models we had trained weren’t ready to be used with TF Lite. This is why we turned to Teachable Machine, which allowed us to train and develop prototype models to be used with TF Lite.
If you’re not familiar with Teachable Machine, I recommend taking a look 😉 https://teachablemachine.withgoogle.com
Once the model was trained in the Teachable Machine, we obtained a compressed file containing 2 files:
- labels.txt: It contains the complete list of the trained classes, in this case, the 25 species, plus an extra class for background noise.
- soundclassifier_with_metadata.tflitemodel: The TensorFlow Lite model is ready to be integrated into our application.
Now it was time to integrate it into our Flutter application.
For this, we used tflite_audio. We started by placing the Teachable Machine files inside the project, renaming them to frogs_labels.txt and frogs_model.tflite. We added them to pubspec.yaml and got them ready to be used by the library.

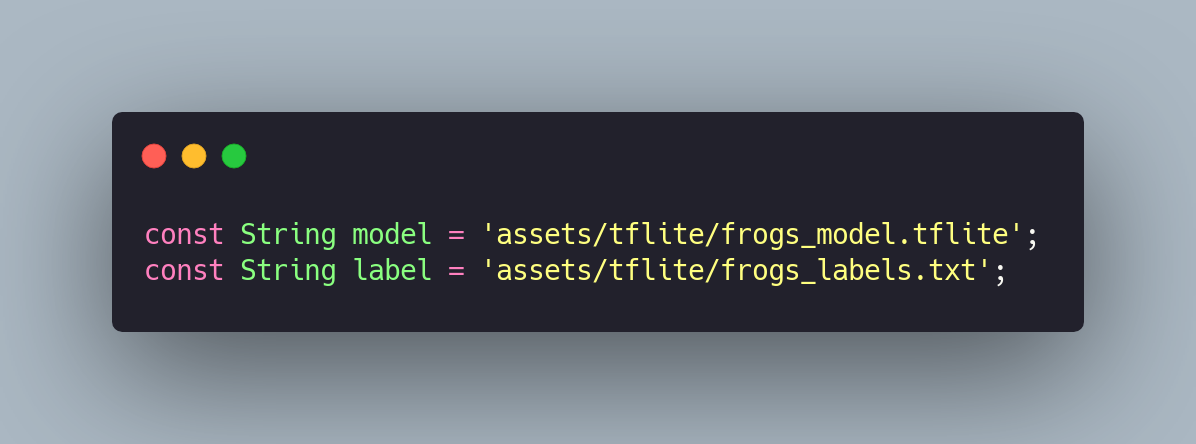 pubspec.yaml
pubspec.yaml
After importing the library, we initialized it by assigning the previously mentioned model and labels.

Regarding the following attributes:
- inputType: As we are using a model developed with Teachable Machine, it’s necessary to set the value to ‘rawInput’.
- isAsset: In case our model and labels are located, for example, in external storage, this attribute should be set to false. In our case, both are located in the ‘assets’ folder of the project.
- outputRawScores: By setting this attribute to true, we are asking the library to return the detection accuracy levels corresponding to each of the trained classes.
It’s important to clarify that the values returned by the library when activating the outputRawScores are in string format as follows.

Because of this, it was necessary to convert the string to an array in order to access each of the values individually and in double format.
 outputRawScores an array
outputRawScores an array
The first position of the array refers to the first class in the labels file.
So, we could establish the connection between both lists and thus understand what the model was recognizing.
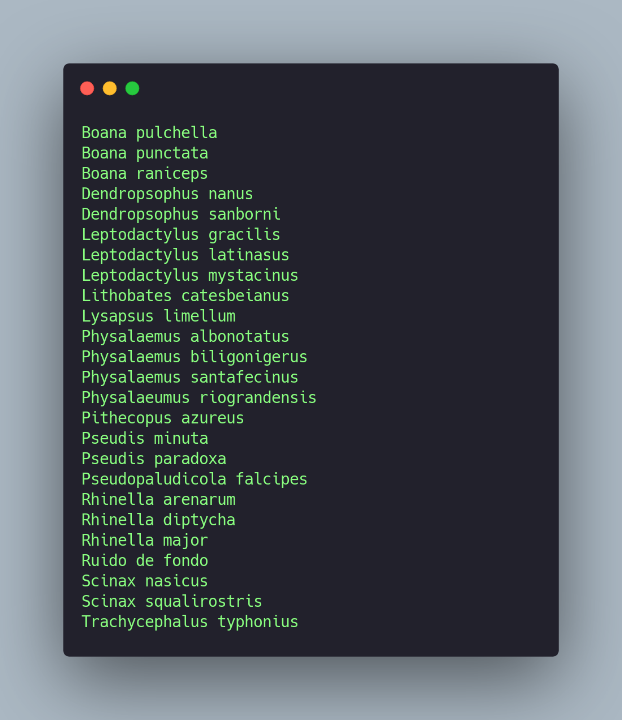
 Labels
Labels
For recording, it wasn’t necessary to use any additional library; tflite_audio already has what’s needed to perform real-time recording and recognize the trained classes.
To initiate recording and recognition, we need to invoke the method from the library startAudioRecognitionand configure some initial attributes.
startAudioRecognition records small 1-second segments which are then analyzed by the model.
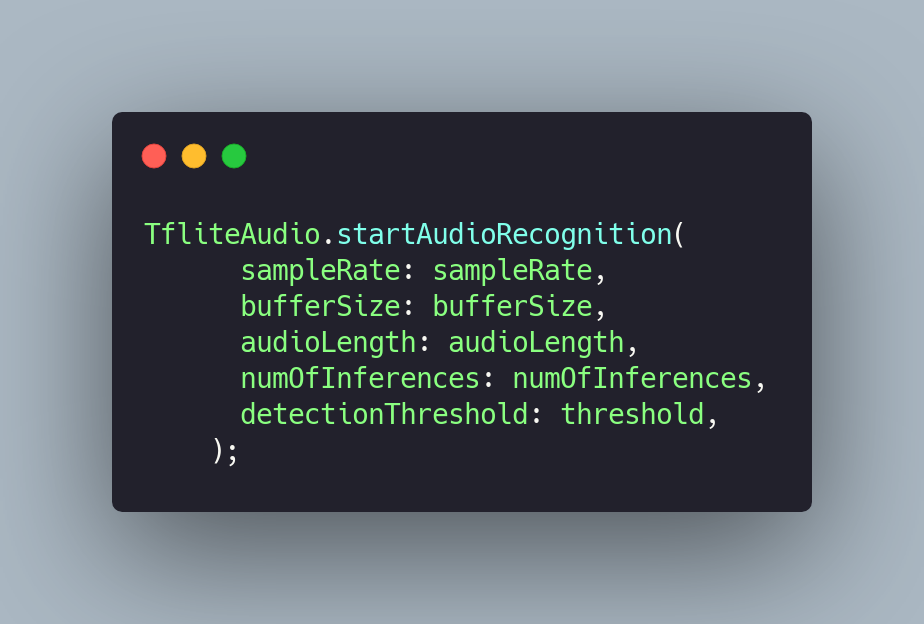
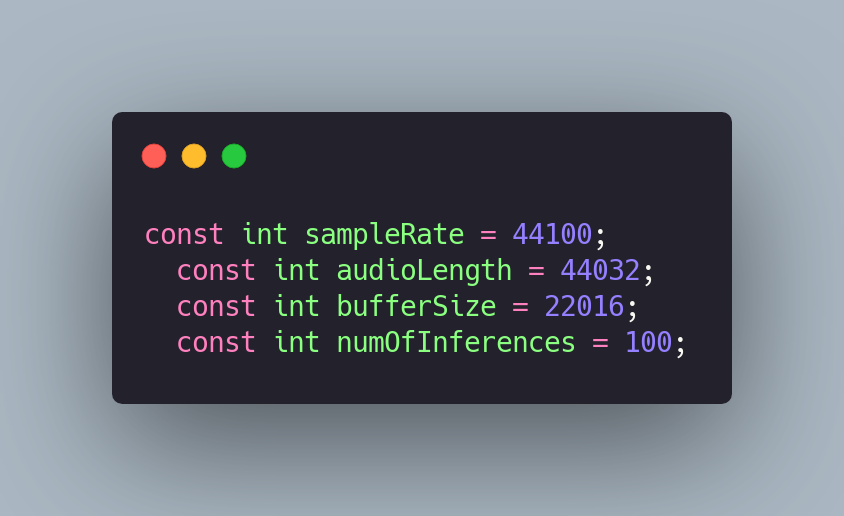
Some of these attributes are tied to the characteristics of the dataset used to train the model. For instance, if the audio dataset was recorded with a sample rate of 16 kHz, the attribute should be configured with the same value. Similarly, when configuring audioLength and bufferSize.
If you want to learn more about Sample Rate, Audio Length, and Buffer Size, I recommend reading the following article from Adobe https://www.adobe.com/uk/creativecloud/video/discover/audio-sampling.html
In our case, we used the following values since the audio recordings were made using a Teachable Machine, and these are the values the platform uses for training.
Lastly, there are numOfInference and detectionThreshold.
As I mentioned before, when invoking the startAudioRecognition method, it records 1-second segments. numOfInference determines how many times or cycles these segments will be recorded and analyzed. If we assign a value of 2, the library will be active for 2 seconds, with 1 second per cycle.
It’s crucial to find the value where the model performs best. In some cases, the higher the number, the greater the accuracy over time. But this isn’t always the case.

detectionThreshold is the value at which we ignore predictions that don't exceed this threshold.
Once the library is configured, startAudioRecognition will return an event stream that we can easily access.
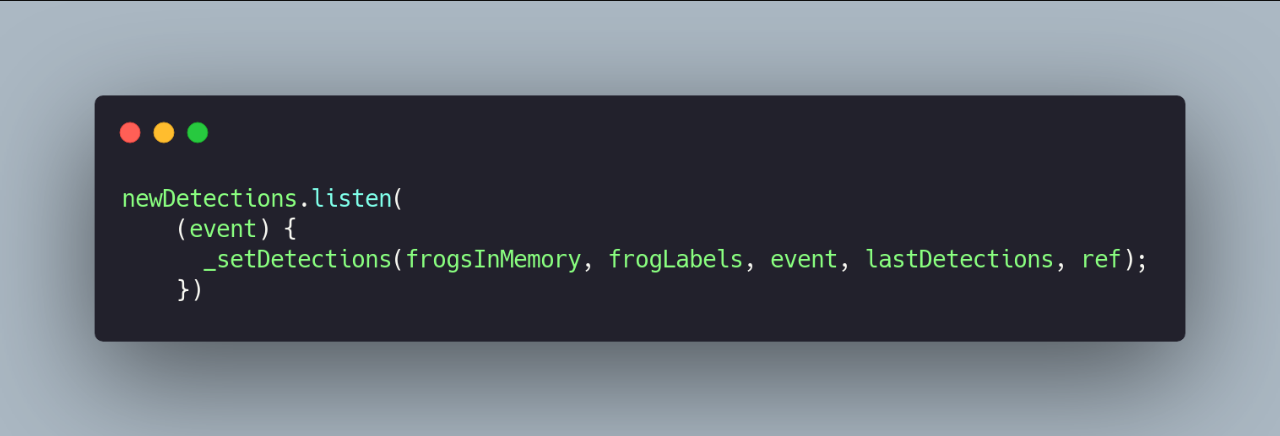
In our case, using Riverpod, we store these values and display them in real-time on the main screen.
And that’s it!
Thank you for coming this far. 😊
See you in the next post! 👋🖖
REFERENCES
WEBSITES
- Teachable machine https://teachablemachine.withgoogle.com/train/audio
LIBRARIES USED
- For the audio recognition tflite_audio.
- For state handling with flutter_riverpod.
Do you want to develop an app in Flutter? Learn more about us at https://mtc-flutter.com/ Follow us on Instagram @mtc.morethancode